
Trust in Chatbots and Taxonomy of Breakdowns
Project Year: 2020
Background and Motivation
- Mental health apps are increasingly prevalent, 12,000+ mental health apps available (Schueller et al., 2019)
- Apps and content around mental health are largely unregulated (Neary and Schueller, 2018), few apps backed up by research/RCTs/efficacy data
- Chatbots are increasingly utilized in this domain (e.g., Woebot, Wysa, Replika)
- Breakdowns in communication decrease trust in chatbots (Ashktorab et al., 2019)
Research Questions:
- What features lead to increased perceptions of trustworthiness and competence in mental health chatbots?
- Hypothesis: Greater presence of communication breakdowns will lead to decreased perceptions of trust and working alliance
- Working Alliance: client/therapist relationship and shared goals toward positive change
- Hypothesis: Greater presence of communication breakdowns will lead to decreased perceptions of trust and working alliance
Methods used: Diary Study, Standardized Scales
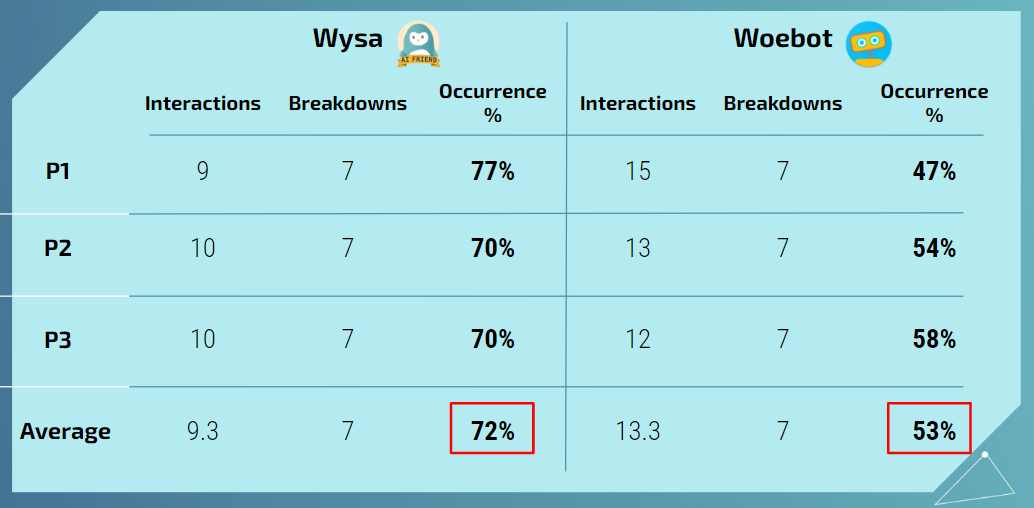
- Compared two mental health chatbot apps - Wysa and Woebot
- Diary Study - Participants used each app and kept a log of: Duration of conversations, Communication breakdowns experienced, Empathetic expressions or chatbot self-referencing
- Pre- and post- study surveys containing:
- Source Credibility Measure (trust and competence)
- Working Alliance Inventory
- Dependent Variables: Measures of Trust, Competence, and Working Alliance
- Independent Variable: Number of communication breakdowns/errors
Participants
- 3 participants, 10 days using each of the two apps
- Participants chatted with Woebot daily for an average of 9.7 minutes and with Wysa daily for an average of 13.2 minutes
Results
P1: It [Woebot] seemed to genuinely care about how I was feeling, it was patient and respected my space (if I wanted it), and wanted me to feel better
P2: [Wysa] Repetitive not only in the activities, but also the CBT theories - every time, it says why the thought is unhelpful and how I can fix that by using positive thinking. There is no variation in its education
P3: Wysa is obviously unpolished. Woebot’s conversations felt fluid, restricted, and clear. Unlike that, Wysa’s conversations can be disrupted by bugs, innocuous treatment and interaction.
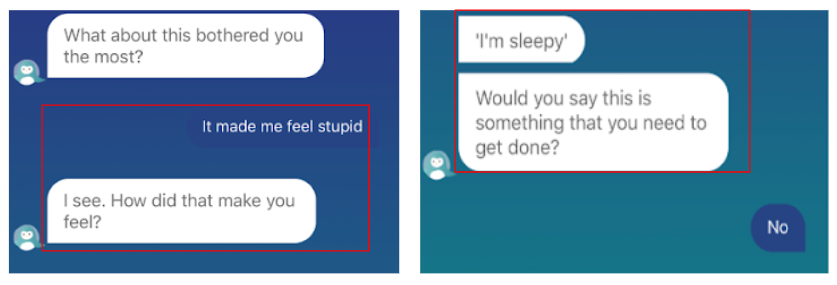
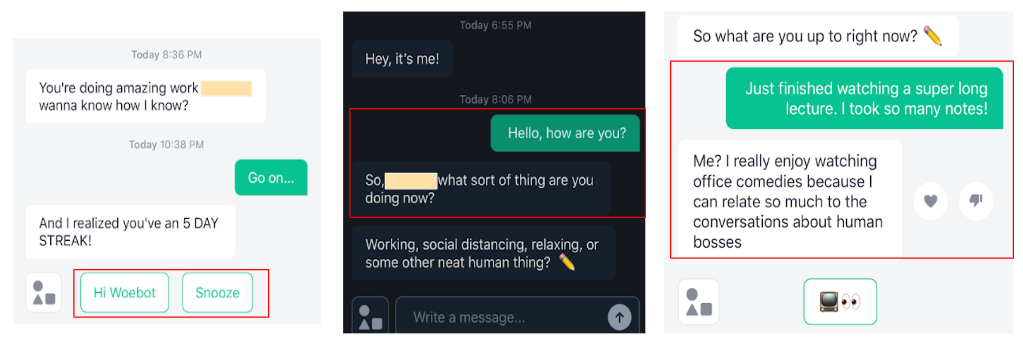
Types of Breakdowns
| Conversation Flow | Misunderstandings/Inability to respond | Glitches |
|---|---|---|
| Offering strange presets | Lack of acknowledgment | Typos |
| Abrupt shifts in topics | Inability to respond to emojis | Repeated queries/circular convos |
| Ill-timed Jokes | Inability to understand free text | Lack of timely response |
| Illusion of choice | Continuing to an activity a user declined | |
| Providing two options that are both yeses | Perceiving positive emotions as negative | |
| Lack of variety - must fit into the closest option |
Examples of Conversation Breakdowns
Working Alliance Inventory (WAI)
- Score out of 60 possible, higher = greater WA
| Wysa | Woebot | |
|---|---|---|
| P1 | 25 | 35 |
| P2 | 29 | 44 |
| P3 | 20 | 28 |
| Average | 24.7 | 35.7 |
Source Credibility Measure (SCM)
- Each subset score out of 42 possible, higher = better
| Wysa | Woebot | |
|---|---|---|
| Competence (avg) | 21.3 | 28 |
| P1 | 21 | 26 |
| P2 | 19 | 33 |
| P3 | 24 | 25 |
| Caring (avg) | 25 | 34.3 |
| P1 | 21 | 36 |
| P2 | 31 | 36 |
| P3 | 23 | 31 |
| Trust (avg) | 27.7 | 33.3 |
| P1 | 29 | 3 |
| P2 | 29 | 34 |
| P3 | 25 | 32 |
Discussion
Woebot
- Chatbot is the only feature
- Higher SCM + WAI scores
- Offers few free-text responses - less room for misunderstanding
- Still saw breakdowns though
- Woebot asks for feedback on individual messages, and at the end of each conversation
Wysa
- Chatbot is not the main feature
- Solely free-text responses open the app up to breakdowns
- May expect more from free response as it’s more advanced
- Offers only negative mood options - difficult to discuss positive days
- Users felt like they had to carry the conversation
- Felt like more of a machine, whereas Woebot felt like more of a friend